之前小凯seo博客和朋友们分享的是Meltdown & Spectre 攻击及缓解措施(一),今天的再和朋友们分享一下Meltdown & Spectre 攻击及缓解措施(二),这篇内容也是由百度安全指数平台在2018年1月9日发布的,正文部分如下:
4. 攻击能力分析
a、Spectre攻击
Spectre攻击有两个变种,V1可以用于绕过内存访问的边界检查,V2可以通过分支预测注入(对CPU分值预测机制的干扰)来执行代码。
到2018年为止,几乎所有的计算机系统都收到Spectre攻击的影响,包括几乎所有的服务器、桌面电脑、笔记本和移动设备。特别的是,Spectre不仅影响Intel,还影响AMD和基于ARM的处理器 [8, 2]。Intel通过官方声明对Spectre攻击进行了回应。AMD则回应称,由于AMD处理器结构的不同 [1],V2攻击对AMD处理器几乎是不可能的。
BoundsCheck Bypass – V1
V1攻击可以用于绕过内存访问的边界检查,核心是利用了推测执行可以执行条件分支语句之后的指令这一性质。攻击者可以利用V1攻击来执行特定的代码片段(gadget),获取其无权限获取的内存空间的内容。一个可被用于V1攻击的代码片段例子如:
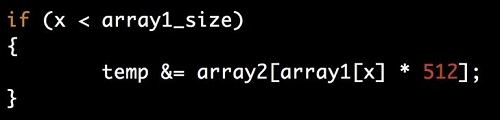
图1:可以被V1利用的典型代码片段(gadget)。注意这里的x必须为攻击者能够影响,否则这个代码不可以被利用发起攻击。
这种方法恶意的利用了CPU的推测执行功能,在CPU做分支判断期间(数十个CPU cycle内)在推测执行模式下执行if语句块内的部分。在V1攻击中,攻击者在推测执行的分支中恶意执行一个越界内存访问。虽然推测执行模式下的内存访问不会被最后真实执行,但是其访问的信息很有可能会被攻击者用其他的方法感知(例如使用基于时间的侧信道攻击)。此外,感知泄露到的内存内容还可以用于构造控制流劫持的exploit。
BranchTarget Injection – V2
V2攻击主要利用分支预测机制进行攻击。其主要思路利用CPU内部的间接跳转预测器(Indirect branch predictor),在推测执行模式下执行特定代码片段。攻击者可以通过许多方法影响甚至控制间接跳转预测器的行为,使得间接跳转预测器会预测执行攻击者指定位置的代码,从而在推测执行下执行攻击者想要的代码片段。条件跳转指令可以分成两种:条件直接跳转和条件间接跳转。条件直接跳转很难被用于V2攻击,因为其跳转的目标位置代码通常是不可控的。条件间接跳转可以被用于V2攻击,因为其跳转的目标地址有可能被攻击者控制。攻击者通过控制条件间接跳转的目标位置,或是其目标位置的代码,使得跳转目标处的指令片段对于隐私数据(例如密钥、token等)有相当强的side-effect,再使用侧信道感知推测执行模式下产生的side-effect来推测隐私数据(密钥、token),从而完成攻击。由于不同的CPU的间接跳转预测器原理不同,因此对CPU的间接跳转预测器进行干扰、注入的方法也各不相同。此外,超线程模式下,跑在同一个CPU核心上的两个线程和间接跳转预测器之间也有相当复杂的关系,也有可能参与到V2攻击中。
关于ASLR
为了完成攻击,攻击者需要在污染指令的虚拟地址(Virtual Address)上与被攻击目标的虚拟地址满足一定的约束,从而污染目标的预测分支。因此,理论上如果有完善的地址空间随机化(ASLR),那么攻击者很难有效的完成攻击。但是由于现有ASLR机制经常有信息泄露,因此攻击者在对目标系统进行充分研究后,往往有机会构造出成功的漏洞利用代码。为了进行有效的防护,往往需要更细粒度、更安全的ASLR防护。
关于预测执行中的内存加载时延
预测执行的时间是有限的,比如V1只有数十个CPU Cycle。而攻击目标的内存数据如果不在cache里,很有可能从DRAM中加载目标数据就不止数十个CPU Cycle,从而无法在时间限制内完成完整的攻击流程。
针对这种情况,攻击者可能可以简单的发起多次攻击。前次攻击虽然无法完成完整的攻击流程,但会将目标内存数据加载进Cache,从而使得后继的攻击不用再阻塞在内存加载上。但是这个可能性还未被确认成功,现有的PoC也无法对任意内核地址进行攻击以获得成功。
b、Meltdown攻击 – V3
V3攻击可以被用于从用户态读取内核态数据。通常来说,如果用户态程序直接访问内核的内存区域会直接产生一个页错误(由于页表权限限制)。然而,在特定条件下,攻击者可以利用推测执行机制来间接获取内核内存区域的内容。例如,在某些实现中,推测执行的指令序列会将缓存在L1 Cache中的数据传递给随后的指令进行操作(并影响Cache状态)。这会导致用户态程序能通过Cache侧信道的方式推测得到内核态数据。需要注意的是该攻击只限于已被内核分配页表的内存(在页表里被标为supervisor-only),被标为not present的内存区域是不能被攻击的。
Meltdown漏洞主要影响Intel处理器,而对AMD处理器几乎无效。Intel声明该缺陷几乎影响其发售的所有处理器,AMD则声称其处理器并不存在此缺陷 [7]。ARM声称主流的ARM处理器不受该漏洞影响,并发布了一份受影响的处理器列表。然而ARM的Cortex-A75处理器直接受Meltdown漏洞影响,同时Cortex-A57、Cortex-A72受到Meltdown漏洞变种的影响 [7]。同时,Raspberry Pi平台不受所有Meltdown和Spectre漏洞的影响。
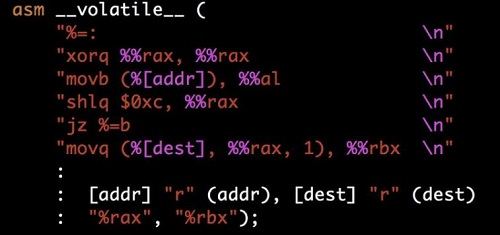
图2:典型的Meltdown攻击代码样例。
c、浏览器攻击
在浏览器中,可以通过JavaScript或者WebAssembly进行攻击代码构造。但是这样的攻击面临着几个严重的限制。
首先是ASLR,V1/V2攻击需要对可执行代码的地址做精确控制,而现代浏览器都部署了地址随机化。由于BTB碰撞只依赖于虚拟地址的低bit位,所以理论上攻击者依然有机会通过大内存段堆风水操作以及多次尝试来实现攻击,但在浏览器环境下,目前尚没有高效的攻击方法出现。
已有的JavaScript V1攻击,充分利用了同一个浏览器内部的相对地址固定的前提,完成了浏览器内部的跨站数据获取。但是对于V1攻击,要有可控的index来操纵越界读,在PoC中可以直接传输。但对于现实场景下,寻找到可用的目标脚本片段也是一个很大的挑战。
对于V3攻击,由于JavaScript引擎会检查数组越界,所以无法直接发起V3攻击。但是可以结合V1攻击,形成V3c组合攻击。但是这依然受限于ASLR。要发起有意义的攻击,需要结合其他的安全漏洞获取地址泄露信息,或者做长时间大范围的内存扫描。此外,由于JavaScript的Array index类型长度是一个32bit整数 [11],所以很难在64bit系统上有效的指向kernel内存区域。Web Assembly会提供比JavaScript更合适的攻击环境,但单独的攻击实战意义依然有限。
5. 缓解方案
边界检查绕过的缓解 – V1的缓解
V1攻击高度依赖于特殊的代码片段(gadget)。因此,简单有效的软件解决方案就是插入一个barrier来阻止推测运行机制在这段特殊代码里面执行。Barrier可以选用LFENCE指令。MFENCE同样可以,不过它的性能损失比LFENCE大。

图3:加入LFENCE指令在判断语句之后,防止后面的代码执行推测运行机制。
对于Linux系统,禁用eBPF机制可以阻断现有PoC攻击,使得攻击者无法通过eBPF接口注入V1 gadget到内核空间,从而显著提升exploit的构造难度。Intel的一个分析报告 [3]指出,可以作为V1攻击的代码片段在Linux内核中很少。这样使得攻击者发起V1攻击的可行性降低。
跳转目标注入攻击的缓解 – V2的缓解
对于跳转目标注入攻击,有两个可行的缓解方案。
RSB 填充 + BTB 刷新。这是一个纯软件解决方案。其核心思想就是对跳转目标的buffer, 即RSB和BTB进行清理,使得攻击者注入的跳转目标不再有效。因为RSB是一个32个槽的循环buffer,因此只需要32个虚假的call指令就可以把整个RSB清理一遍(实例代码如图4所示)。BTB的槽从1K到16K不等,而且从虚拟地址到BTB索引的映射函数f(x)还不公开,因此要清除BTB,需要首先使用逆向工程方法找到f(x),然后根据f(x)找到1k到16K的虚拟地址来对应每个BTB的槽。最后发起1K到16K个虚假的call/jmp把所有BTB的槽清空(实例代码如图5所示)。需要指出,该方案的性能overhead很大。
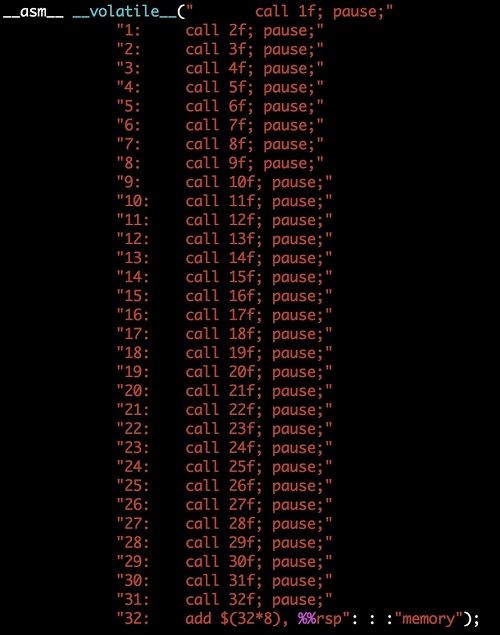
图4:RSB Padding。32个虚假call来清空RSB。
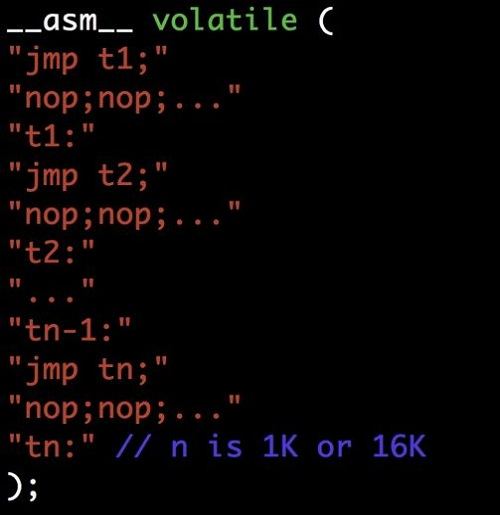
图5:BTB Flushing。使用1K或16K跳转来清空BTB。
微码升级 + 系统软件(VMM/kernel)补丁.这个缓解方案需要CPU微码升级和系统软件(VMM/kernel)更新。CPU微码的升级提供了三个新的接口给系统软件:
a、Indirect Branch Restricted Speculation (IBRS)。当IBRS被设置上时,高优先级代码不会使用低优先级的跳转地址。比如VMM不会使用任何VM提供的地址,kernel也不会使用任何用户进程提供的地址。
b、Single Thread Indirect Branch Predictors (STIBP)。当STIBP被设置上时,同一物理CPU上的两个HyperThreading逻辑内核直接的跳转地址不再共享。
c、Indirect Branch Predictor Barrier (IBPB)。当IBPB被设置时,之前的跳转地址不会影响之后的跳转预测。这个功能一般用于从高优先级到低优先级切换上下文的时候。比如VMM回到VM或kernel回到用户空间。
这三个功能是否支持可以用CPUID加ax=0x7来检测。返回结果中rdx的第26位表明这三个新功能是否支持。对系统软件(VMM/kernel)的更新,各个操作系统已经发布了相关的补丁。
如果无法得到微码升级,可以考虑使用Retpoline指令替换技术 [10] 进行防御,替换掉容易被V2攻击的间接跳转和间接调用指令。
此外,类似于V1,Linux下关闭eBPF也可以有效的提升V2攻击的难度。
Meltdown攻击的缓解措施 – V3的缓解
抵御Meltdown攻击最有效的方式就是KAISER/KPTI。KAISER/KPTI方案中要求操作系统维护两个页表,一个页表给用户程序使用,一个给kernel自己使用。并且确保程序所使用的页表不会映射高优先级的页面,即不会映射kernel的页面。KAISER/KPTI方案最早提出时是为了侧信道攻击对内核地址随机化(KASLR)的影响。该方案恰巧也可以用来抵御Meltdown攻击。
两个页表的切换,会导致CR3的重新加载,从而引起TLB刷新,进而降低内存的访问速度。如果某些应用场景需要大量的内核和用户空间切换(两个页表之间的切换),会造成较高的性能开销。为了降低这些性能开销,kernel需要使用充分的利用PCID特性,把TLB的刷新降低。
了解跟多:https://mp.weixin.qq.com/s/Bdc58fRJO4nFzCHnO5WIYQ