对于百度蜘蛛Baiduspider的认识和了解也是作为seoer所必须要懂得的内容之一,只有掌握了如何正确识别Baiduspider百度蜘蛛的技术,对网站的优化效果及发展状况的了解由很大的帮助。那么到底怎么样进行baiduspider的识别呢,今天小凯seo博客转载一篇来自于百度站长平台的文章,内容详细的介绍了识别Baiduspider的方法。以下是正文部分:
如何正确识别Baiduspider移动ua
新版移动ua:
Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
PC ua:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
之前通过“+http://www.baidu.com/search/spider.html”进行识别的网站请注意!您需要修改识别方式,新的正确的识别Baiduspider移动ua的方法如下:
1. 通过关键词“Android”或者“Mobile”来进行识别,判断为移动访问或者抓取。
2. 通过关键词“Baiduspider/2.0”,判断为百度爬虫。
另外需要强调的是,对于robots封禁,如果封禁的agent是Baiduspider,会对PC和移动同时生效。即,无论是PC还是移动Baiduspider,都不会对封禁对象进行抓取。之所以要强调这一点,是发现有些代码适配站点(同一个url,PC ua打开的时候是PC页,移动ua打开的时候是移动页),想通过设置robots的agent封禁达到只让移动Baiduspider抓取的目的,但由于PC和移动Baiduspider的agent都是Baiduspider,这种方法是非常不可取的。
如何识别百度蜘蛛
百度蜘蛛对于站长来说可谓上宾,可是我们曾经遇到站长这样提问:我们如何判断疯狂抓我们网站内容的蜘蛛是不是百度的?其实站长可以通过DNS反查IP的方式判断某只spider是否来自百度搜索引擎。根据平台不同验证方法不同,如linux/windows/os三种平台下的验证方法分别如下:
1、在linux平台下,您可以使用host ip命令反解ip来判断是否来自Baiduspider的抓取。Baiduspider的hostname以 *.baidu.com 或 *.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即为冒充。
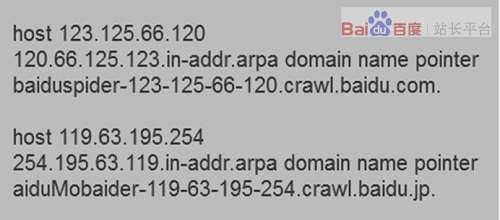
2、在windows平台或者IBM OS/2平台下,您可以使用nslookup ip命令反解ip来 判断是否来自Baiduspider的抓取。打开命令处理器 输入nslookup xxx.xxx.xxx.xxx(IP地 址)就能解析ip, 来判断是否来自Baiduspider的抓取,Baiduspider的hostname以*.baidu.com 或*.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即为冒充。
3、 在mac os平台下,您可以使用dig 命令反解ip来 判断是否来自Baiduspider的抓取。打开命令处理器 输入dig xxx.xxx.xxx.xxx(IP地 址)就能解析ip, 来判断是否来自Baiduspider的抓取,Baiduspider的hostname以 *.baidu.com 或*.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即为冒充。
Baiduspider IP是多少
即便很多站长知道了如何判断百度蜘蛛,仍然会不断地问“百度蜘蛛IP是多少”。我们理解站长的意思,是想将百度蜘蛛所在IP加入白名单,只准白名单下IP对网站进行抓取,避免被采集等行为。
但我们不建议站长这样做。虽然百度蜘蛛的确有一个IP池,真实IP在这个IP池内切换,但是我们无法保证这个IP池整体不会发生变化。所以,我们建议站长勤看日志,发现恶意蜘蛛后放入黑名单,以保证百度的正常抓取。
同时,我们再次强调,通过IP来分辨百度蜘蛛的属性是非常可笑的事情,所谓的“沙盒蜘蛛”“降权蜘蛛”等等是从来都不存在的。